Eine Datei enthält zunächst nur eine Bytefolge. Es gibt 2 verschiedene Grundtypen von Dateien; sie unterscheiden sich darin, für welchen Adressaten die enthaltenen Daten gedacht sind:
Programm-Dateien enthalten Prozessor-Befehle;
Daten-Dateien enthalten Benutzer-Informationen.
Dateien werden durch charakteristische Namenserweiterungen gekennzeichnet. So enden die Namen von Programm-Dateien z.B. auf ".EXE", ".COM" oder ".DLL". Fast alle anderen Erweiterungen kennzeichnen eine Datei als Daten-Datei. So weisen Erweiterungen wie "TXT", "DOC", "BMP", "JPEG" usw. daraufhin, welche Art von Informationen in der Datei enthalten ist, und auf welche Weise diese Informationen in der jeweiligen Bytefolge kodiert sind. Eine solche Zuordnung zwischen Daten und Informationen nennt man ein Format.
In der Byte-Folge einer Daten-Datei sind also Informationen für den Benutzer enthalten. Allerdings kann er diese Informationen in der Regel nicht direkt aus den Daten entnehmen. Er braucht dazu ein Programm, das ihm die in den Daten verborgenen Informationen in einer für ihn verständlichen Form zeigt und darüberhinaus eine Weiterbearbeitung (Löschen, Ändern, Hinzufügen) ermöglicht. Ein solches Programm nennt man einen Editor für das entsprechende Format.
Beispiele:
"Word" ist ein Editor für Dateien im DOC-Format.
"Paint" ist ein Editor für Dateien im BMP-Format.
"Excel" ist ein Editor für Dateien im XLS-Format.
"Maple" ist ein Editor für Dateien im MWS-Format.
"DynaGeo" ist ein Editor für Dateien im GEO-Format.
"IrfanView" ist in diesem Sinne kein Editor für irgend ein Grafik-Format, da das Programm keine Bearbeitung der eigentlichen Bildinhalte erlaubt. Es handelt sich hier um einen "Viewer" ("Betrachter"), mit dem man die Grafiken nur anzeigen, aber nicht ändern kann. Darüberhinaus ist das Programm ein leistungsfähiger "Konvertierer" zwischen verschiedenen Grafik-Formaten.
Der Benutzer hat nicht unbedingt für jede Daten-Datei, die er auf seiner Festplatte vorfindet, einen passenden Editor. Manche dieser Dateien enthalten auch gar keine Daten für den Benutzer, sondern Daten über den Benutzer, wie z.B. "INI"- oder "REG"-Dateien. In diesen Fällen werden die Daten von Programmen oder dem Betriebssystem gebraucht, z.B. um benutzerspezifische Einstellungen für ein Programm oder die Desktop-Oberfläche zu speichern.
Ein Dokument ist nun eine Daten-Datei, für die der Benutzer einen Editor hat. Dokumente enthalten also die Daten, die der Benutzer bearbeiten kann. Der zugehörige Editor erschließt ihm die enthaltenen Informationen und ermöglicht ihre Bearbeitung sowie die Speicherung der geänderten Daten.
Dokumente sind damit die für den Benutzer wichtigsten und wertvollsten Dateien auf seinem Computer, denn sie enthalten seine Daten in transportierbarer Form. Programme (auch das Betriebssystem) lassen sich ohne Schwierigkeiten wieder restaurieren, wenn das auch im allgemeinen etwas Mühe macht. Verlorene Dokumente hingegen sind oft überhaupt nicht wieder zu beschaffen! Bei der Datensicherung sollte man sich also in allererster Linie um seine Dokumente kümmern!
Hat ein Byte in einer Datei einen bestimmten Wert, so liegt damit noch nicht fest, welche Information damit kodiert wird. Dies kann man erst entscheiden, wenn der Datentyp bekannt ist, also die Art und Weise, wie dieses Byte interpretiert werden soll.
Beispiel:
Eine Datei enthält im 134. Byte den Wert 73h. Dieser Wert kann sehr unterschiedliche Informationen tragen:
Handelt es sich um eine Programmdatei, dann könnte dieses Byte z.B. der Anfang eines Befehls sein, der den Prozessor anweist, die Programmausführung an einer bestimmten anderen Stelle des Programmcodes fortzusetzen.
Handelt es sich um eine Datendatei, dann kennen wir schon jetzt mehrere mögliche Bedeutungen dieses Bytes:
Es kann z.B. die natürliche Zahl 115 bedeuten.
Falls die Datendatei eine Textdatei ist, könnte aber auch das ASCII-Zeichen mit der Hex-Nummer 73h gemeint sein, also das Zeichen "s".
In einer RLE-Grafikdatei könnte das Zeichen einen Run von 115 Pixeln gleicher Farbe kodieren.
Will man also einem Daten-Element die enthaltene Information entnehmen, dann muss man den Typ dieses Elements kennen. Die Situation auf der Ebene der Daten ist also analog zu der, die wir bei Dateien vorgefunden haben: auch dort gab es verschiedene Typen von Dateien, die durch ihre jeweilige Namens-Erweiterung einem bestimmten Format ("Datei-Typ") zuzuordnen waren. Analog gibt es also auch für die einzelnen Daten-Elemente zugehörige "Formate", d.h. Datentypen:
Inhalt wird dargestellt durch
Interpretation wird ermöglicht durch
Dateien
Bytefolge
Dateiformat (kurz: "Format")
Daten-Elemente
Bytefolge
Datentyp (kurz: "Typ")
In der Informatik ist stets streng zu unterscheiden, ob man mit einer Bezeichnung ein Element oder einen Typ meint. Ein Beispiel soll den Unterschied verdeutlichen: Wenn Schnuffi und Wuffi die beiden Hunde des Nachbarn sind, dann handelt es sich hier um zwei konkrete Exemplare der biologischen Art Hund. Im Sinne der Informatik ist Hund also die Typ-Bezeichnung, während Schnuffi und Wuffi Bezeichnungen für zwei konkrete Hunde-Exemplare sind. Solche konkreten Exemplare nennen wir Instanzen: Schnuffi und Wuffi sind Instanzen des Typs Hund.
Selbstverständlich gibt es noch zahlreiche andere Instanzen vom Typ Hund. Es gibt sogar so viele unterschiedliche Instanzen, dass es sich lohnt, im Zoo der Hunde durch Bildung von "Untertypen" (wie z.B. Schäferhund, Terrier, Dackel usw.) für etwas mehr Übersicht zu sorgen. Setzt man die Klassifizierung entsprechend fort, dann können so ganze "Typ-Bäume" entstehen. Wenn z.B. Schnuffi ein Dackel ist, dann ist Schnuffi also eine Instanz des Typs Dackel. Und da alle Dackel auch Hunde sind, ist Schnuffi natürlich auch weiterhin ein Hund. Man kann also sagen, dass Typen die Verwandtschaften zwischen Instanzen regeln.
In diesem Kapitel soll geklärt werden, nach welchen Prinzipien eine Beschreibung eines Verfahrens formuliert werden muss, damit sie zur Lösung eines Problems taugt. Darüberhinaus wollen wir einen Überblick darüber erhalten, welche verschiedenen sprach-logischen Elemente eine solche Beschreibung enthalten kann. Es wird sich herausstellen, dass man erstaunlicherweise mit relativ wenigen Grundstrukturen auskommt, egal wie kompliziert das zu beschreibende Verfahren auch sein mag.
Im Kapitel 5 wurde ein RLE-Format für Schwarz-Weiß-Bilder beschrieben. Wir wollen nun nochmals einen genaueren Blick auf die Kodierungsvorschrift werfen:
Kodierung:
Wir denken uns alle Pixel des Bildes in der unter 2a) und 2b) beschriebenen Reihenfolge in einer "Pixelschlange" aufgereiht.
Setze die "aktive Farbe" auf "schwarz".
Wiederhole nun die folgenden Schritte.... {
Bestimme die Anzahl n der am Anfang der Schlange aufeinander folgenden Pixel, die die aktive Farbe haben. Dabei darf n höchstens 255 werden. Gibt es mehr als 255 "aktiv"-farbige Pixel hintereinander, dann halte beim 255. Pixel an.
Schreibe das Byte n in die Daten.
Streiche die schon gezählten Pixel ab, d.h.: die Schlange beginnt nun mit dem ersten noch nicht gezählten Pixel.
Wenn die aktive Farbe "schwarz" ist, dann:
schalte sie auf "weiß" um,
andernfalls:
schalte sie auf "schwarz" um.
}
....solange, bis keine Pixel mehr in der "Schlange" sind.
Was passiert hier? Wenn jemand diesen Anweisungen folgt, dann erzeugt er aus einem Strom von Eingangsdaten (dem Pixelbild) einen Strom von Ausgangsdaten (den Datei-Inhalt). Solche Vorschriften, die beschreiben, wie aus Eingangsdaten Ausgangsdaten erzeugt werden sollen, nennen Informatiker einen Algorithmus. Man kann sich einen Algorithmus als eine Maschine vorstellen, die aus einer Eingabe eine bestimmte Ausgabe erzeugt:
Damit der Algorithmus das gestellte Problem auch wirklich lösen kann, müssen an ihn hohe Anforderungen gestellt werden:
er darf nur endlich viele Anweisungen enthalten;
jede Anweisung muss eindeutig formuliert sein;
jede Anweisung muss ausführbar sein;
das Verfahren muss nach einer endlichen Anzahl von Schritten "terminieren".
Das oben zitierte Kodierungsverfahren erfüllt all diese Forderungen, also handelt es sich hier um einen Algorithmus. Schauen wir uns den Text im Hinblick auf seine sprachlogische Konstruktion nochmals genauer an:
Wir denken uns alle Pixel des Bildes in der unter 2a) und 2b) beschriebenen Reihenfolge in einer "Pixelschlange" aufgereiht.
Setze die "aktive Farbe" auf "schwarz".
Wiederhole nun die folgenden Schritte....
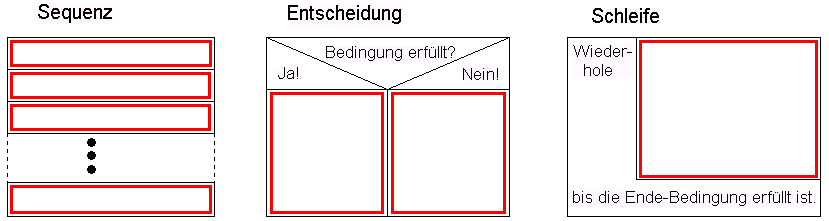
Dies ist eine Folge von Anweisungen. Durch die Reihenfolge ist der zeitliche Ablauf festgelegt, in dem die einzelnen Aktionen auszuführen sind. Eine solche lineare Folge von Anweisungen nennt man eine Sequenz.
Die Anweisung 3 enthält innerhalb der geschweiften Klammern ihrerseits wieder eine Sequenz, nämlich die Anweisungen (i), (ii), (iii) und (iv). Interessanter ist jedoch der "Rahmen" um diese Sequenz:
Wiederhole nun die folgenden Schritte....
{
(i), (ii), (iii), (iv)
}
....solange, bis keine Pixel mehr in der "Schlange" sind.
Eine solche Konstruktion nennt man eine Schleife: die Anweisung(en) im Schleifenkörper sind zu wiederholen, bis die Bedingung für das Ende der Schleife erfüllt ist.
Die Anweisung (iv) enthält eine logische Alternative:
Wenn die aktive Farbe "schwarz" ist, dann:
schalte sie auf "weiß" um,
andernfalls:
schalte sie auf "schwarz" um.
Je nach dem, ob der Wert der aktuellen Farbe "schwarz" ist oder nicht, ist also die eine oder die andere Aktion durchzuführen. Eine solche Konstruktion nennt man eine Entscheidung: wenn die Entscheidungs-Bedingung erfüllt ist, ist die eine Anweisung auszuführen, wenn nicht, dann die andere.
Die drei sprachlogischen Grundkonstruktionen Sequenz, Entscheidung und Schleife können nun mit beliebiger Tiefe ineinander geschachtelt werden. Und dies reicht aus, um jeden denkbaren Algorithmus zu formulieren! Sequenz, Entscheidung und Schleife sind also die universellen Bausteine, aus denen sich jeder noch so komplizierte Algorithmus aufbauen läßt.
Für die übersichtliche Präsentation von Algorithmen kann man graphische Darstellungen der obigen drei Grundstrukturen benutzen, z.B.:
Dabei kann in jedem der rot umrandeten Kästen entweder eine Anweisung oder wiederum eine Sequenz, eine Entscheidung oder eine Schleife stehen. Die aus diesen Bausteinen erstellten Diagramme nennt man Struktogramme, weil sie die (logische) Struktur des Algorithmus veranschaulichen. Zum Beispiel sieht der oben schon zitierte RLE-Kodierungs-Algorithmus (in einer leicht gekürzten Fassung) in Struktogramm-Darstellung folgendermaßen aus:
So schön diese Struktogramme auch aussehen, wenn sie denn erst mal fertig sind, so mühsam ist es, sie zu erstellen! Das Problem ist, dass man eigentlich schon wissen muss, wieviel Platz man für welchen Teil des Struktogramms brauchen wird, bevor man überhaupt anfängt. Angesichts dieser Situation kommen doch gewisse Zweifel auf, ob Struktogramme wirklich ein vernünftiges Arbeitsmittel für die Phase des Algorithmen-Entwurfs sind! Eine ganz entscheidende Hilfe bietet hier das Freeware-Tools StruktEd von Michael Bellinghausen! Mit diesem Struktogramm-Editor können Sie hemmungslos an Ihrem Struktogramm-Entwurf "herum-designen", ohne sich auch nur einmal um Platzprobleme kümmern zu müssen: der Editor kümmert sich selbstständig und erfolgreich um alle Formatierungsfragen, während Sie sich ganz auf die inhaltlichen Probleme konzentrieren können!
Aufgaben:
Der RLE-Algorithmus enthält an einer Stelle eine reichlich komplexe Anweisung, die eigentlich nur für einen mathematisch gebildeten Menschen verständlich ist, sicher aber nicht für einen Computer, nämlich die Anweisung (3.i):
Bestimme die Anzahl n der am Anfang der Schlange aufeinander folgenden Pixel, die die aktive Farbe haben. Dabei darf n höchstens 255 werden. Gibt es mehr als 255 "aktiv"-farbige Pixel hintereinander, dann halte beim 255. Pixel an.
Zerlegen Sie diese Anweisung in "kleinere Häppchen", und stellen Sie den Teil-Algorithmus in einem eigenen Struktogramm dar.
Erstellen Sie ein Struktogramm für einen Algorithmus, des aus einer Menge von k Zahlen den größten Wert heraussucht. Obwohl sich diese Aufgabe recht ähnlich anhört wie die vorige, erfordert sie wahrscheinlich doch einen ganz anderen Lösungsansatz!
Stellen Sie den Algorithmus zum Bestimmen der Lösungsmenge einer linearen Gleichung der Form "a*x + b = 0" mit einem Struktogramm dar! Beachten Sie dabei, dass hier verschiedene Fälle zu unterscheiden sind, je nachdem, ob a oder b von Null verschieden sind oder nicht. Daher greift die Idee "x = -b/a" zu kurz. Vergessen Sie auch nicht den Fall "a = b = 0": selbst für "0*x + 0 = 0" sollte Ihr Algorithmus die korrekte Lösungsmenge liefern!
Wenn Sie die vorige Aufgabe erfolgreich gemeistert haben, können Sie sich an ein etwas schwierigeres Problem wagen: lösen Sie die entsprechende Aufgabe für quadratische Gleichungen der Form "a*x² + b*x + c = 0"! Sie können dabei voraussetzen, dass es sich bei der gegebenen Gleichung wirklich um eine echte quadratische Gleichung handelt, mit anderen Worten: a darf als verschieden von Null vorausgesetzt werden. Bemühen Sie aber auch bei dieser Aufgabe darum, dass Ihr Algorithmus für alle dann noch möglichen Varianten des Problems stets die korrekte Lösungsmenge liefert!
Wer eine richtig leistungsfähige Algorithmensammlung aufbauen will, wird die quadratische Gleichung aus der vorigen Aufgabe etwas allgemeiner sehen: in "a*x² + b*x + c = 0" sollen nun beliebige Werte für a, b und c zugelassen werden! Damit muss Ihr Algorithmus nun auch den Fall "a = 0" behandeln.
Durchforsten Sie Mama's Kochbuch nach einem Rezept, dessen Struktogramm-Darstellung alle drei Grundstrukturen enthält. Stellen Sie das Rezept in einem Struktogramm dar.
Obwohl Rezepte häufig als Standard-Beispiel für Algorithmen herhalten müssen, eignen sie sich eigentlich denkbar schlecht dafür: üblicherweise sind sie nämlich so formuliert, dass keine strikte Trennung zwischen dem eigentlichen Algorithmus und seinen Eingangsdaten erkennbar ist.